本文是 Stochastic Calculus for Finance II: Continuous-Time Models 第 1 章与《微观金融学及其数学基础》第 9 章的部分笔记,简单梳理了基于测度论的概率论的基本概念:
- 概率的公理化定义
- 随机变量与分布
- 随机变量的期望
- 随机变量的收敛方式
微观金融研究领域中有两大核心概念:不确定性,以及时间或动态过程。而概率论便是用于构造不确定环境下金融模型的基本工具。在本文里,我们会借助测度论的语言,将我们以前学过的初等概率论中的概念重新表述一遍,了解如何“说好现代概率论里的行话”。
为什么要在概率论中引入测度论呢?假如我就想用初等概率论来解决问题不行吗?不是不可以,但是初等概率论所能解决的问题实在有限。举个简单的例子。就以「扔一枚均匀硬币」的随机试验为例。当我扔硬币的次数仅限于有限次的时候,你可以用以前学过的概率论知识算出扔出正面的概率是多少。但是,如果我不停扔这枚均匀硬币,问你永远都是正面的概率是多少,你也许可以用初等概率论的方法告诉我是0。但如果你再仔细想下去,想想我问你这个事件发生的概率的时候,我到底是在问什么呢?换而言之,「概率」是什么?你可能没有仔细思考过这个概念。你并没有真的认真深入的思考过这个问题,因为实际上当你的概率空间是无穷次抛硬币的结果的时候,就不像抛有限次的情况,因为你不能对所有“事件”定义概率了。另一个例子是,条件期望是什么?什么叫某个随机变量 X 一定时另一个随机变量 Y 的期望?虽然直观上好像可以理解成“平均值”,但很难用初等概率论给出一般情况下的严格定义的,可能需要分类讨论X, Y是连续或离散随机变量,或他们的混合,或更复杂。
你可能对「概率」有些懵懂的认识:或许你会将其视作某个事件在多次重复实验中发生的频率,或许你认为概率是自己于某个事件可能发生的信服程度,亦或者,你可能将其视作逻辑的扩展(如果你是这么想的话,那你或许能在 E.T.Jaynes 所著的 Probability Theory: The Logic of Science 找到共鸣)。但是光有观念还不够,为了使用现成的、方便的定量方法解决问题,你还得深究下去,想办法办法把你的这些观念转化成数学语言,把你想要达到的目标转写成良定义的问题——测度论就是一种可选的语言,可用于说清楚「概率」到底是什么。
本章的具体内容如下:第一,简要回顾初等概率论中对于概率及随机变量的定义,用严格的测度语言表述它们;第二,考察在随机分析中非常重要的期望与条件期望的概念与相关性质;第三,进一步考察随机变量的主要数值特征,借助这些数值特征,描述几个在研究金融资产价格运动时必须牢固把握的概率分布;第四,对于随机变量的收敛进行简要探讨。
如何描述概率——概率的公理化定义
粗略地讲,概率就是衡量「事件发生的可能性」的大小。可是,「事件」是什么?「可能性」又是什么?一种可行的思路是,可以借助集合论与测度论中的工具对于上述概念进行指代:用集合代表「事件」,集合系代表「事件的全体」,集合的测度代表「事件发生的可能性」。
下文将尝试用测度的语言,从5个步骤入手1,表述现代概率公理体系。为了便于理解,下文的阐述均基于「连续投掷2次硬币」这个随机试验。在「连续投掷2次硬币」这一随机试验中,将硬币的某一面记作正面,与其相反的一面记作反面。将「硬币投出了正面」记作 H (假设其可能性为 $p,p>0$),将「硬币投出了反面」记作 T (假设其可能性为 $q, q=1-p>0$)。
描述样本空间——$\Omega$
以一串序列($w_1w_2w_3\cdots w_n$,其中$w_i的可能取值为H或T$)列出所有可能发生的结果,便可得样本空间 $\Omega$ : $$ \Omega = \lbrace \text{HH, HT, TH, TT}\rbrace. $$
描述事件——$\Omega$ 的子集
样本空间 $\Omega$ 列出了随机试验所有可能发生的结果。在这些过程中,有一些结果可能是我们 所关心的。例如,我们可能会 关心第1次掷币的结果是正面 或者 关心第2次掷币的结果是反面。根据我们 所关心的 内容不同,我们可以对样本空间中的元素进行归类。这种归类有个学名,叫分割(decomposition)。其定义如下:对于一族集合$\lbrace C_i, i=1,2,\cdots\rbrace$,如果 $ C_i\cap C_j=\varnothing, \forall i \neq j $ 且 $\cup^\infty _{i=1}C_i=\Omega$ ,则称这一族集合 $\lbrace C_i, i=1,2,\cdots\rbrace$ 为 $\Omega$ 的一个分割(decomposition)或划分(partition)。
为了更好地理解分割,我们来看这样一个例子:$\lbrace C_1=第1次掷币的结果是正面\rbrace;$$ \lbrace C_2=第1次掷币的结果是反面\rbrace $是 $\Omega$ 的子集。由于 $C_1= \lbrace \text{HH, HT}\rbrace, C_2= \lbrace \text{TH, TT}\rbrace$,因此 $ C_1\cap C_2=\varnothing$ 且 $C_1 \cup C_2 = \Omega$,所以 $\lbrace \text{HH, HT}\rbrace, \lbrace \text{TH, TT}\rbrace$ 是 $\Omega$ 的一个分割。同理可得,$\lbrace \text{HH}\rbrace,\lbrace \text{HT}\rbrace,\lbrace \text{TH}\rbrace,\lbrace \text{TT}\rbrace$ 也是 $\Omega$ 的一个分割2。
理解了分割后,便可以对事件进行定义了。所谓事件,就是由样本空间 $\Omega$ 的某一种分割通过不断的集合运算构造出的一些集合。比如说,「第1次掷币的结果是正面」这一事件就是 $\lbrace \text{HH}\rbrace,\lbrace \text{HT}\rbrace$ 基本分割的并,也可以是 $\lbrace \text{TH}\rbrace,\lbrace \text{TT}\rbrace$ 两个基本分割并集的补。又比如说,「第1次掷币的结果既不是正面也不是反面」这一事件就是 $\lbrace \text{HH}\rbrace,\lbrace \text{HT}\rbrace,\lbrace \text{TH}\rbrace,\lbrace \text{TT}\rbrace$ 基本分割并集的补,即 $\varnothing$,因此称该事件为不可能事件3;而「第1次掷币的结果是正面或反面」这一事件就是 $\lbrace \text{HH}\rbrace,\lbrace \text{HT}\rbrace,\lbrace \text{TH}\rbrace,\lbrace \text{TT}\rbrace$ 基本分割的并集,即 $\Omega$,称其为确定事件。
描述事件的集合——$\sigma-$代数 $ \mathcal{F}$
在上一小节中,我们利用分割与集合的基本运算描述了事件的概念。如果对这些事件进一步施加一系列集合的基本运算,似乎就能将所有我们所关心的事件都表示成集合的形式。把我们所关心的事件全部列出来以后,我们好像就可以 对这些事件对应的集合定义它们的测度,进而衡量这些集合对应的事件发生的可能性了。未来似乎一片光明啊~
可是,事情并没有那么简单。如果重新审视上文下划线的表述,我们又会碰上 2 个问题:
- 我们关心的是某些事件发生的可能性,对应的是相应集合的测度。然而,不是每一个事件都可以被定义出概率的,也并不是每个集合都可以被定义出测度。
- 在我们考虑不同的事件时,势必要对不同的事件进行组合、操作,将这些事件组合为更加复杂的事件。在这些操作中,会涉及集合的交、并、差等运算。万一运算出来的集合不在我们处理的能力范围内,那可咋整啊?
第 1 个问题要求我们 找出那些能被定义测度的集合,即所谓可测集,将它们作为我们的研究对象,而第 2 个问题要求我们经过组合操作后所得到的输出结果,与输入内容的类型一致,仍然是可测集,因此需要 找到这样的一个集合系,使得其中的集合在经过可数次运算后的结果不会超出这个集合系所能包含的范围。那么,在集合论与测度论的工具箱里,是否有能够满足上述用下划线所标识的性质的工具呢?实际上,测度论中提到了这样的一个集合系,不仅可以保证其中的集合是可测集,而且这些集合对基本运算封闭。这个集合系,便是$\sigma-$代数,其定义如下:

$sigma-代数$的定义
简单解释一下 $\sigma-$代数 的含义。$\sigma-$代数 是以集合为元素的集合。从定义1.1中的3个性质入手,可以推出集合系中的空集、可数次交/并/差、上限集、下限集在运算后都能在该集合系中。通俗来说,$\sigma-$代数 里的某1个元素都代表1个最基本的事件,而 $\sigma-$代数 的某1个子集就代表1个更加复杂的事件。如果样本空间 $\Omega$ 中可能发生的情况共有 $N$ 种,那么由 $\Omega$ 中的元素经过集合运算生成的最小 $\sigma$-代数 就是 $\mathcal{F} = \lbrace \varnothing, \Omega \rbrace$,最大的 $\sigma$-代数 就是由所有的幂集构成,一共包含 $2^N$ 个元素。
为了更好地理解$\sigma-$代数,接下来让我们看由基本分割产生的 $\sigma-$代数(记作$\mathcal{F}$)。定义$\lbrace \text{HH}\rbrace,\lbrace \text{HT}\rbrace,\lbrace \text{TH}\rbrace,\lbrace \text{TT}\rbrace$ 这个基本分割,通过交、并、补所得的 $\sigma-$代数 包含 16 个元素,它们是:
$$ \mathcal{F} = \lbrace \varnothing, \Omega, \lbrace \text{HH}\rbrace,\lbrace \text{HT}\rbrace,\lbrace \text{TH}\rbrace, \lbrace \text{TT}\rbrace, \lbrace \text{HH,HT}\rbrace, \lbrace \text{HH,TH}\rbrace, \ \lbrace \text{HH,TT}\rbrace, \lbrace \text{HT,TH}\rbrace, \lbrace \text{HT,TT}\rbrace, \lbrace \text{TH,TT}\rbrace, \ \lbrace \text{HH,HT,TH}\rbrace, \lbrace \text{HH,HT,TT}\rbrace, \lbrace \text{HT,TH,TT}\rbrace, \lbrace \text{HH,TH,TT}\rbrace \rbrace $$ $\sigma-$代数 包含了某一时刻我们所知道的「所有可能发生的事件的所有可能组合」,代表着我们在该时刻所知道的所有信息。比如说,上文由基本分割产生的 $\sigma-$代数 $\mathcal{F}$ 代表了我们对「连续投掷2次硬币」的结果所具备的信息,其中包含了所有可能的结果,表示我们对于「连续投掷2次硬币」这个随机试验已经达到了“全知”的程度。$\sigma$-代数 这种「承载我们所知的信息」的功能,详见这篇文章。
有了样本空间 $\Omega$ 和 $\sigma$-代数 $\mathcal{F}$ 以后,我们可将它们写成 $( \Omega, \mathcal{F} )$,称之为可测空间(measurable space),而 $\mathcal{F}$ 中的元素4称为可测集(measurable set)。至此,我们便初步界定了「随机试验」中所关心的「事件」。接下来需要定义的,就是这些「事件」发生的可能性,即概率了。
描述可测空间上的测度——$\mu$
概率的定义应该从哪里入手呢?不妨试着从我们刚刚得到的可测空间 $( \Omega, \mathcal{F} )$ 入手。 $( \Omega, \mathcal{F} )$ 之所以叫做可测空间,是因为其具备一些优良的性质,使得 $\mathcal{F}$ 中的任意一个集合都可以定义其测度。如果我们在可测空间 $ ( \Omega, \mathcal{F} )$ 上定义一个测度 $\mu$,并进一步让这个测度 $\mathbb{P}$满足某些我们所期望「概率」应该具备的性质,那么不就能对 $\mathcal{F}$ 中的任意一个集合(也就是事件)定义其「可能性的大小」了吗?因此,我们接下来要做的事情就是:1. 定义 $ ( \Omega, \mathcal{F} )$ 上的测度 $\mu$ ;2. 在 $\mu$ 上增加某些性质,使之成为我们心目中的「概率」。
这一节做的是第 1 件事,即定义 $ ( \Omega, \mathcal{F} )$ 上的测度。不严谨地讲,测度实际上是可测空间 $ ( \Omega, \mathcal{F} )$ 上存在的一个从 $\mathcal{F} $ 到 $[0,\infty)$ 的映射,记作 $\mu:\mathcal{F} \rightarrow \text{R}^+$,其定义为:
- $\mu(\varnothing) = 0.$
- $\mu(A)\geq 0, \forall A \in \mathcal{F}.$
- 对于 $\mathcal{F}$ 中任意可数集合 $C_i,i=1,2,\cdots$,如果 $ C_i\cap C_j=\varnothing, \forall i \neq j $ ,有$\mu(\cup^\infty_{i=1} C_i) = \Sigma^\infty_{i=1}\mu(C_i)$.
这样定义的函数关系就是所谓测度(measure)。将测度加入测度空间,则三位一体的 $ ( \Omega, \mathcal{F}, \mathbb{P} )$ 便称为测度空间。
将测度特化为概率测度——$\mathbb{P}$
在第 4 节中测度定义中加上一个正则性要求,即 $\mathbb{P}(\Omega) = 1$,便可构造出 $\mathcal{F}$ 上的一个函数关系 $\mathbb{P}:\mathcal{F} \rightarrow [0,1]$,对于任意一个集合$A\in \mathcal{F}$都制定了$\left[0,1\right]$中的一个数 $\mathbb{P}(A)$。$\mathbb{P}$ 便是我们所要的概率测度,简称为概率,而 $ ( \Omega, \mathcal{F}, \mathbb{P} )$ 便称为概率空间。此时我们便完成了对概率的公理化定义。

概率(测度)的定义
如何方便计算事件的概率——随机变量与分布
给事件贴上实数类型的标签——随机变量 $X$
我们已经有了一系列的公理概念。但是,我们考察的对象都是集合这一类型。如果我们能将集合转化到我们熟知的实数系,就能用上更多好用的运算工具(比如微积分)。为了实现这一点,我们需要引入随机变量这一概念:

随机变量的定义
从直观上理解,假设存在 2 个可测空间 $(\Omega,\mathcal{F})$ 和 $(\text{R},\mathcal{B})$ ,那么随机变量 X 就是这样的一个函数关系 $X:\Omega \rightarrow \text{R}$,其作用相当于为 $\mathcal{F}$ 中的每一个元素(即事件)都安排一个对应的实数,从而将 $ ( \Omega, \mathcal{F}, \mathbb{P} )$ 引导到了一个新的概率空间 $ ( \text{R}, \mathcal{B}, \mathbb{L} )$ 上。
随机变量 $X$ 是一个数值的量,其具体数值由 $\omega \in \Omega$ 的随机试验所确定,可以视作样本空间 $\Omega$ 里事件的别名。因此,我们原本对「事件发生可能性大小」的注意力,就可以转移到对「随机变量 $X$ 取不同值的概率」了。不过,在很多时候,$X$ 取特定值的概率都是 0 。因此,我们将主要考虑 $X$ 取值在某一集合上的概率(即 $\mathbb{P}\lbrace X \in 某个集合\rbrace$),而不是取特定值的概率(即 $\mathbb{P}\lbrace X = 某个特定值\rbrace$)。下一节里我们将通过理解随机变量的分布,了解计算 $X$ 取值在某一集合上的概率。
瞅瞅随机变量取值有啥特征——分布测度 $\mu_X$、累积分布函数 $F$ 与……
简单来说,随机变量的分布用于揭示随机变量 2 方面的信息:1. 可以取到哪些值?2. 取得这些值(连续情况下,则是某一区间)的概率分别是多少?。这种分布,可以通过分布测度,或概率质量函数,或密度函数,进行描述。
先来看个例子。回顾我们一开始「连续投掷2次硬币」随机试验结果的空间 $ ( \Omega, \mathcal{F}, \mathbb{P} )$。给定一个随机变量 $S$,用于表示股票价格,其定义如下:
$$ \begin{align} S_0(\omega) &= 4, \forall \omega \in \Omega \\ S_1(\omega) &= \begin{cases} 8, & 如果 \omega_1=H \ 2, & 如果 \omega_1=T \ \end{cases} \\ S_2(\omega) &= \begin{cases} 16, & 如果 \omega_1=\omega_2=H \ 4, & 如果 \omega_1\neq \omega_2 \ 1, & 如果 \omega_1=\omega_2=T \end{cases} \end{align} $$
这些都是随机变量,它们对于每个可能的掷币结果结果序列,都指定了相应的数值。藉此我们可以计算这些随机变量取不同值的概率,确定这些随机变量的分布。例如, $$ \begin{align} \mathbb{P}\lbrace S_2&=16\rbrace=\mathbb{P}(\lbrace HH \rbrace)=p^2 \\ \mathbb{P}\lbrace S_2&=4\rbrace=\mathbb{P}(\lbrace HT \rbrace \cup \lbrace TH \rbrace)=2pq \\ \mathbb{P}\lbrace S_2&=1\rbrace=\mathbb{P}(\lbrace TT \rbrace )=q^2 \end{align} $$
可以将 $S_2$ 的分布设想为,将数量为 1 的质量分配到三块地方:1 块大小为 $p^2$ 的质量位于 16;1 块大小为 $2pq$ 的质量位于4;1 块大小为 $q^2$ 的位于 1。这样,我们就能全面了解 $S_2$ 的所有可能取值。
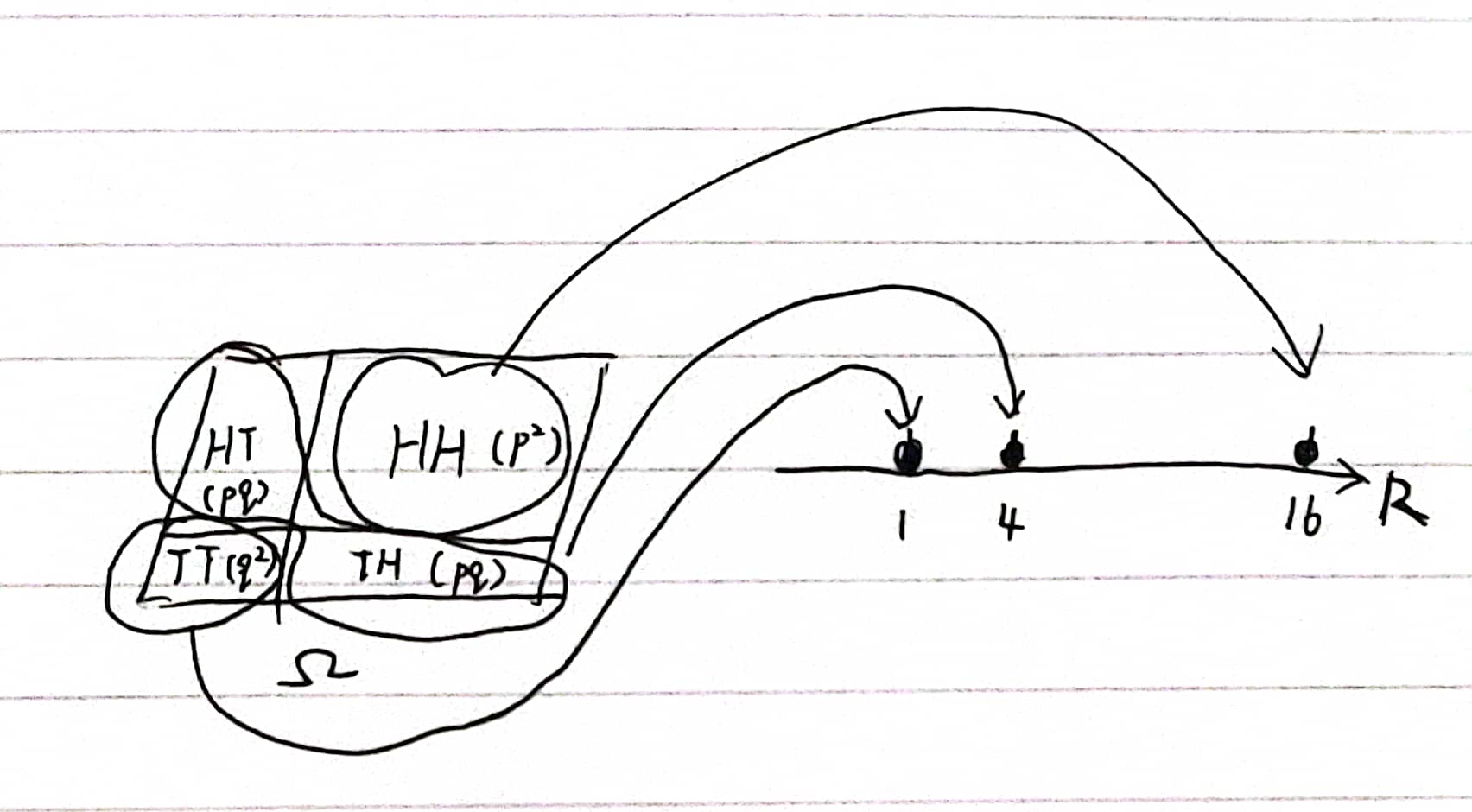
随机变量的用途:将样本空间中的元素映射到实数域中的元素
但是,我们刚才讨论的只是离散情况下的随机变量。如果情况推广到连续情况下,就需要考虑随机变量将单位质量“连续地”分布于整条直线。为此,我们需要将随机变量的分布设想为「在一个集合内有多少质量」,而不是「在某一点有多少质量」。换而言之,随机变量的分布本质上其实也是概率测度,只不过它是在 $\mathbb{R}$ 的子集上的测度。其定义如下:

分布测度的定义
在这个定义中,集合 $B$ 可以仅仅包含一个数。比如说,如果 $B=\lbrace 4\rbrace$,则有 $\mu_{S_2}(B)=2pq$;如果 $B=[2,5]$,我们仍然有 $\mu_{S_2}(B)=2pq$,因为 $S_2$ 在 $[2,5]$ 里只有放在数字 4 的那一块质量。
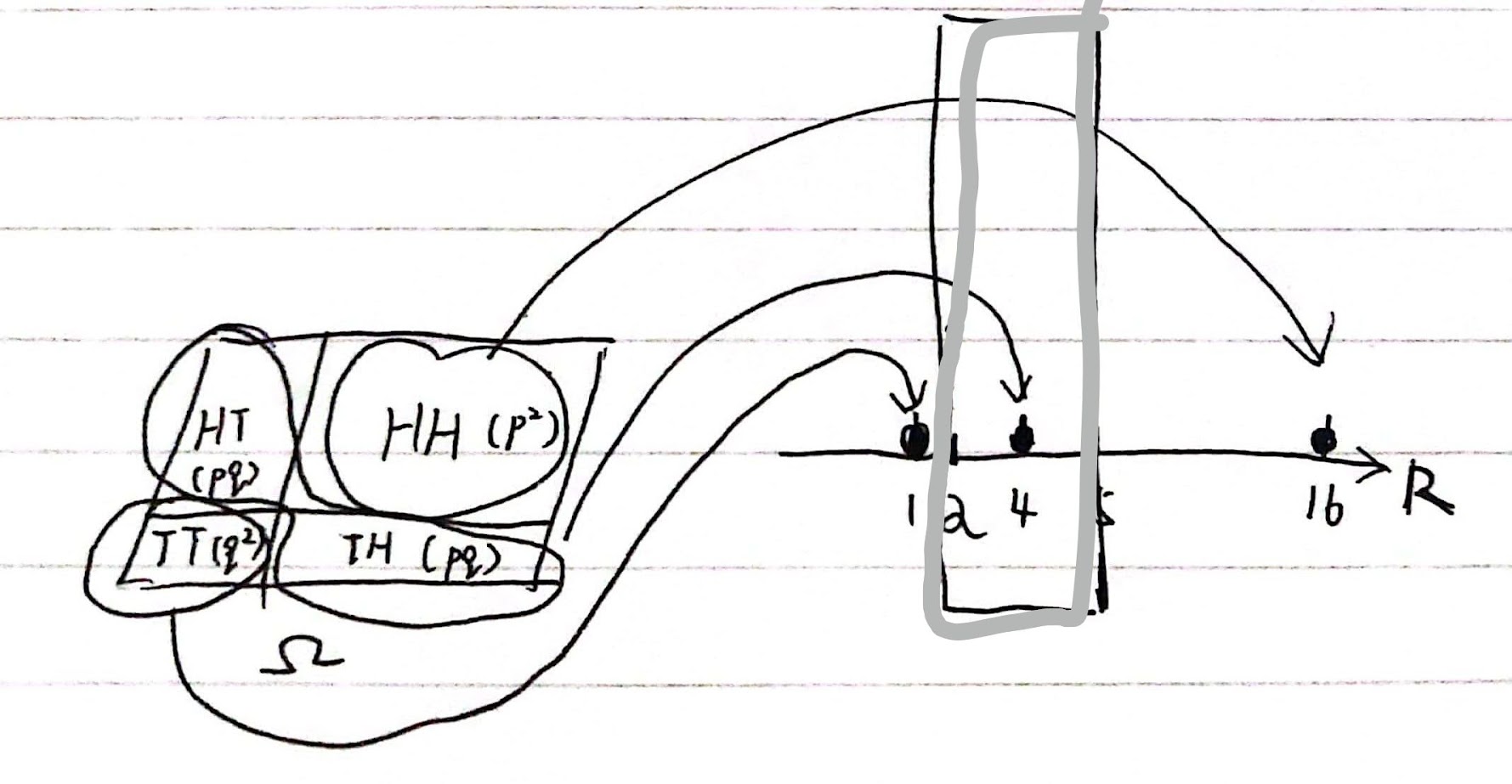
随机变量的用途:将样本空间中的元素映射到实数域中的元素
除了指定分布测度 $\mu_X$ 以外,还有其他记录随机变量的方法。我们可以用累积分布函数来描述随机变量的分布,即:$F(x) = \mathbb{P} \lbrace X\leq x \rbrace, x \in \mathbb{R}$。一方面,如果我们已知分布测度 $\mu_X$ ,则可以通过 $F(x) = \mu_X(-\infty,x]$得到累积分布函数 $F$。另一方面,如果已知累积分布函数 $F$,我们就能计算分布测度 $\mu_X(x,y] = F(y)-F(x)$,其中$x<y $。 在两种特别的情况下,我们可以更详细地描述随机变量的分布。
第一种情况,存在密度函数 $f(x)$,对于所有 $x\in \mathbb{R}$ 有定义,并且满足: $$ \mu_X[a,b] = \mathbb{P}\lbrace a \leq X \leq b\rbrace = \int^b_a f(x)dx, -\infty<a\leq b<\infty $$ 第二种情况,存在概率质量函数,即存在有限序列 $x_1,x_2,\cdots,x_N$ 或者无穷序列 $x_1,x_2,\cdots$ 使得随机变量 $X$ 以概率 1 取序列中的某一个值。定义 $p_i = \mathbb{P}\lbrace X=x_i\rbrace$,则每一个 $p_i$ 非负,并且 $\sum_ip_i=1$。由 $X$ 的分布测度在博雷尔集 $B\subset \mathbb{R}$ 上指定的质量为: $$ \mu_X(B) = \sum_{\lbrace i;x_i \in B\rbrace}{p_i}, B \in \mathcal{B}(\mathbb{R}) $$
某些随机变量的分布可以通过密度函数刻画,而其他的一些随机变量则必须由概率质量函数刻画。不过也存在一些随机变量,其分布由密度函数与概率质量函数混合给出,也有些随机变量的分布既无成块的质量也无密度。
如何知晓随机变量取值的“平均值”——数学期望
设 $X$ 是定义在概率空间 $(\Omega, \mathcal{F}, \mathbb{P})$ 上的随机变量。随机变量的可能取值有很多个,而我们希望计算随机变量的“平均值”,并在计算时考虑到概率的因素。如果 $\Omega$ 是有限空间或者可数的无限空间,便可分别如下计算平均值: $$ \begin{align} \mathbb{E}X &= \sum_{\omega \in \Omega} X(\omega)\mathbb{P}(\omega) \\ \mathbb{E}X &= \sum_{k=1}^\infty X(\omega_k)\mathbb{P}(\omega_k) \end{align} $$ 然而,如果$\Omega$ 是不可数的无限空间,由于不可数的无穷和不能定义,我们只能借助其它工具计算期望。这个工具便是积分。那么,直接用我们之前微积分里学过的黎曼(Riemann)积分可以吗?不太行,因为黎曼积分基本上是设计给连续光滑函数的,只有在充分小的区间上、函数值的改变也非常小的时候才能取到极限。然而,我们现在设计的函数是随机变量,其定义域是事件的集合 $\mathcal{F}$,因此按定义域划分的原则就很难采用:一方面,将 $\mathcal{F}$ 划分为可测集的和,再让这些集合的概率测度趋于 0 ,这种划分方法未必存在;另一方面,即便前面所述的划分方式存在,也只适用于那些在概率测度充分小的集合上 $X$ 的取值改变很小的特殊情况。
因此,我们采用勒贝格积分,通过将函数值域划分为小区间,并进行加总,从而将随机变量的数学期望这个概念转化成了在概率空间 $(\Omega, \mathcal{F}, \mathbb{P})$ 上以概率测度 $\mathbb{P}$) 为积分算子,以随机变量 $X$ 为被积函数的勒贝格积分。
设 $X$ 是概率空间 $(\Omega, \mathcal{F}, \mathbb{P})$ 上的随机变量。勒贝格积分具有下图中的基本性质5:

了解了勒贝格积分的性质后,便可对随机变量的期望进行定义:
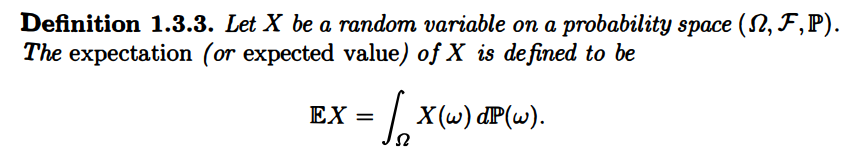 根据勒贝格积分的性质,可得期望的性质:
根据勒贝格积分的性质,可得期望的性质:

下面的定理给出了黎曼积分与勒贝格积分之间的关系。可以说,只要黎曼积分有定义,黎曼积分和勒贝格积分就一定相等,需要计算时,就可以利用微积分学过的计算黎曼积分的技巧处理勒贝格积分。

拓宽极限的概念——随机变量的收敛方式
本节介绍随机变量序列的几种收敛方式——几乎必然收敛、概率收敛、分布收敛和依 m 阶矩收敛以及它们之间的关系。值得一提的是,随机变量序列的几乎必然收敛、概率收敛分别对应一般测度空间上可测函数序列的几乎处处收敛、测度收敛。
以概率 1 收敛
假设 $\lbrace X_n \rbrace_{n \geq 1}$ 是一组定义在概率空间 $ (\Omega, \mathcal{F}, \mathbb{P})$ 上的随机变量序列,$X$ 是定义在同一空间上的随机变量。如果有 $N \in \mathcal{F}$,且 $\mathbb{P}(N)=0$,则对于所有 $\omega \notin N$,随机变量序列 $\lbrace X_n \rbrace_{n \geq 1}$ 在一般意义上收敛于 $X(\omega)$ ,即: $$ \mathbb{P}\lbrace \omega:\lim_{n \to \infty} X_n(\omega) = X(\omega) \rbrace =1 $$ 则称 $\lbrace X_n \rbrace_{n \geq 1}$ 几乎必然或者以概率 1 收敛于$X$,记作:$X_n \stackrel{a.s.} \longrightarrow X$ 或者 $X_n \longrightarrow X \quad w.p.1$。
以概率收敛
假设 $\lbrace X_n \rbrace_{n \geq 1}$ 是一组定义在概率空间 $ (\Omega, \mathcal{F}, \mathbb{P})$ 上的随机变量序列,$X$ 是定义在同一空间上的随机变量。如果对任何 $\epsilon > 0$ ,有: $$ \lim_{n \to \infty} \mathbb{P}(|X_n-X|>\epsilon) = 0 $$ 则称 $\lbrace X_n \rbrace$ 以概率收敛于$X$,记为 $X_n \stackrel{P} \longrightarrow X$ 。这表明随机变量 $X_n$ 与 $X$ 发生任意确定的正偏差的概率随着n的无限增大而趋近于 0 。
依分布收敛
假设 $\lbrace X_n \rbrace_{n \geq 1}$ 是一组定义在概率空间 $(\Omega, \mathcal{F}, \mathbb{P})$ 上的随机变量序列,设 $\lbrace X_n \rbrace$ 的分布函数是 $\mathcal{D}_n, n=1,2,\cdots$,$X$ 的分布函数是 $\mathcal{D}$。如果对于 $\mathcal{D}$ 的每一个连续点 $x$ 都有:
$$ \lim_{n\to \infty} \mathcal{D}_n(x) = \mathcal{D}(x) $$ 则称 $\lbrace X_n \rbrace$ 依分布收敛于$X$,记为 $X_n \stackrel{\mathcal{D}} \longrightarrow X$ 。
依 m 阶矩收敛
假设 $\lbrace X_n \rbrace_{n \geq 1}$ 是一组定义在概率空间 $ (\Omega, \mathcal{F}, \mathbb{P})$ 上的随机变量序列,$X$ 是定义在同一空间上的随机变量。如果: $$ \lim_{n \to \infty}E(X_n-X)^m=0 $$ 则称 $X_n$ 依 $m$ 阶矩(moment)收敛于 $X$ 。特别地,当 $m=1$ 时称为均值收敛,$m=2$时称为在均方意义上收敛(mean square convergence)。
这几种收敛方式的关系如下图所示6。其中,箭头符号代表起始端点代表的收敛方式蕴含终点端点代表的收敛方式。
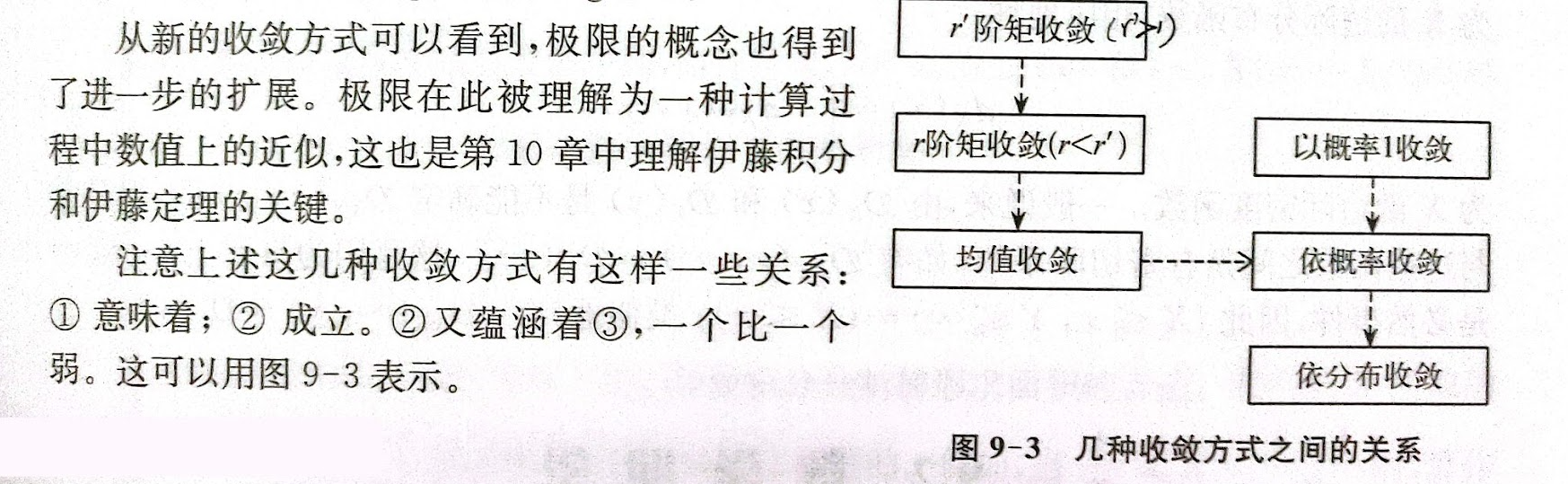
随机变量的收敛方式
总结
本文简单介绍了基于测度论的概率论,以随机试验的样本空间 $\Omega$ 为起点,在此基础上选取了 $\Omega$ 中使概率有定义的子集族 $\mathcal{F}$,并且定义了从 $\mathcal{F}$ 映射到 $[0,1]$ 的函数 $\mathbb{P}$,称之为概率测度。样本空间 $\Omega$ 、子集族 $\mathcal{F}$、概率测度 $\mathbb{P}$ 一同组成了概率空间 $ ( \Omega, \mathcal{F}, \mathbb{P} )$ ,该空间以 $\mathbb{P}(\Omega) = 1$ 及 可数可加性:互不相交集合的概率等于各集合的概率之和 为 2 条公理。
在此基础上,本文介绍了随机变量及其分布。从直观上理解,假设存在 2 个可测空间 $(\Omega,\mathcal{F})$ 和 $(\text{R},\mathcal{B})$ ,那么随机变量 X 就是这样的一个函数关系 $X:\Omega \rightarrow \text{R}$,其作用相当于为 $\mathcal{F}$ 中的每一个元素(即事件)都安排一个对应的实数,从而将 $ ( \Omega, \mathcal{F}, \mathbb{P} )$ 引导到了一个新的概率空间 $ ( \text{R}, \mathcal{B}, \mathbb{L} )$ 上。随机变量 $X$ 是一个数值的量,其具体数值由 $\omega \in \Omega$ 的随机试验所确定,可以视作样本空间 $\Omega$ 里事件的别名。
另外,本文简单介绍了随机变量期望的定义方式:勒贝格积分,以及随机变量的收敛方式:几乎必然收敛、概率收敛、分布收敛和依 m 阶矩收敛。
参考文献
-
此处参考了 微观金融学及其数学基础 P597 的内容。 ↩︎
-
而且这种分割相比前一种分割更加精细。 ↩︎
-
不失一般性地,此处我们不考虑硬币投掷后竖直立起来的情况。 ↩︎
-
其中的元素都是集合哦。 ↩︎
-
这一节中的图片截自 Stochastic Calculus for Finance II: Continuous-Time Models 的 1.3 小节。 ↩︎
-
该图出自 微观金融学及其数学基础 P605。 ↩︎